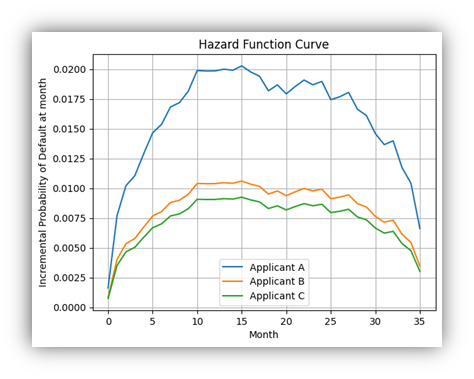
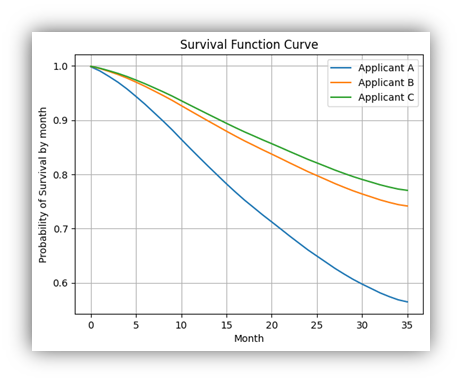
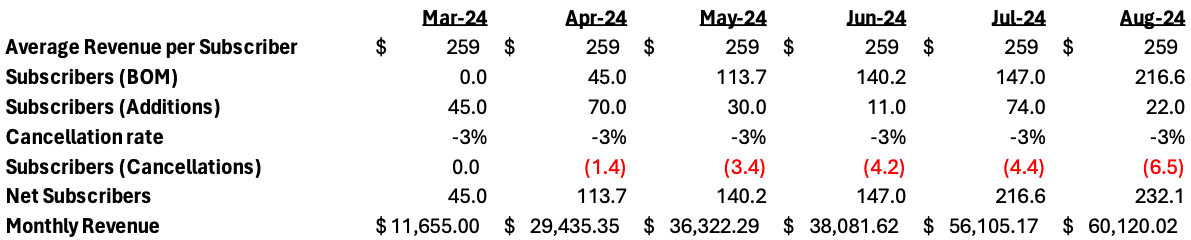In a recent post on recurring revenue financial modeling, I covered some of the main drivers that play a role in the construction of financial forecasts for SaaS and related business models. One of the most important aspects of such financial forecasts is the build out of contracted revenues. In general contracted revenues can be quite predictable, which makes the recurring revenue model so attractive to investors.
The Basics
In a basic format, the recurring revenue forecasting for a good financial model will have the following components to calculate the monthly revenue:
Average revenue per subscriber
Number of subscribers, beginning of the month (past bookings)
Number of subscribers added in the month (new bookings)
Composite cancellation rate (the expected % of existing subscribers who will cancel in the month)
Number of subscribers lost in the month (2*4, cancellations or churn)
Net number of subscribers (2+3-5)
Revenue for the month (1*6)
The image below shows a recurring revenue forecast based on the above calculations. It is necessary to understand that in this kind of model, the limited variations in average revenue and cancellation rates lend themselves to a composite view of the revenue build. If these underlying simplifications are reliable, the above methodology works just fine.
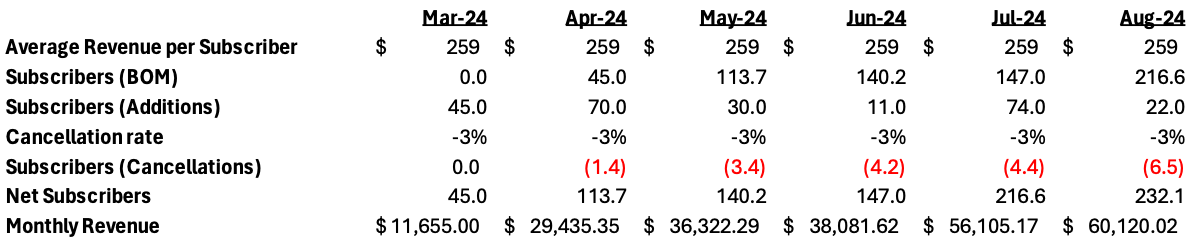
Pro-tip: Unless you have some strong need, I allow subscribers to be calculated in fractions and avoid any rounding functions for subscriber counts. I find partial clients (even though there is no such thing) makes models easier to manage because rounding functions sometimes have unintended consequences and also require maintenance and awareness of their use when other people are using your model.
More complex subscriber calculations
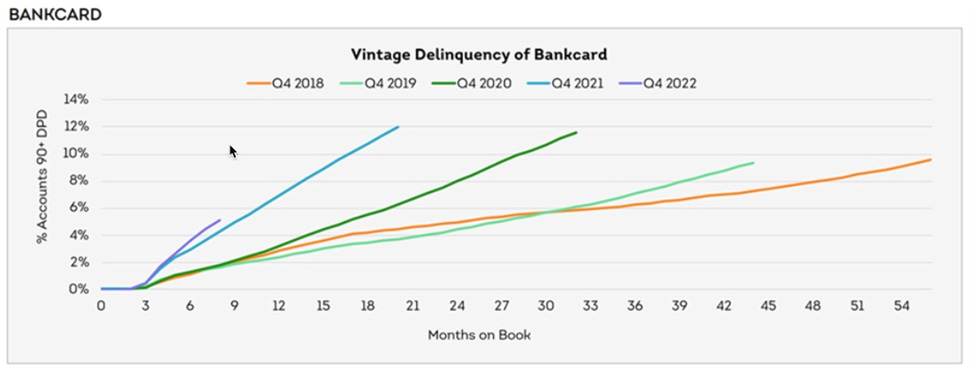
But, what if average revenue per subscriber changes for each new cohort of subscribers and the cancellations vary based on the age of the client. In this case, the value of the existing contracted backlog and the forecast of future contracted backlog becomes much more complex. You can stick to the above methodology, but with cancellations being age dependent, you could be in for hidden surprises and also leave your operations teams with a less refined set of objectives when they are trying to reduce cancellations.
One way to resolve this complexity is to look at a cohort-based backlog, which accounts for the average revenue variation by specifically assigning a revenue amount to a cohort and also assigning a cancellation percentage to each cohort based on its age. In this kind of model, each cohort is assigned a date of birth (sometimes called a vintage) so that it can be tracked uniquely throughout time.
The image below shows what the cancellations would look like in a cohort-based format. (I am intentionally ignoring revenue variations, but this would use a similar methodology to accommodate that variation.) Notice how each month of the model needs to have a cancellation percentage for each cohort.

Compared to the basic format at the beginning of this post, the cohort-based format has turned into a matrix instead of being a single vector (line) of the spreadsheet. In fact, to do this precisely, each line of the basic format should become a matrix. Then instead of multiplying lines in Excel, you multiply across matrices to get to revenue.
Using rough math, the composite cancellation rate in the matrix is about 3% over the March to August time frame. However, you can see that the Aug-24 ending revenues in the cohort-based format ($59,420) are slightly lower than the basic format ($60,120). Now you might think that the $700 (1.1%) is not a big deal, but over time and with increased volume this variance will grow and lead to weaker forecasting. While I would love to use a simpler model for expediency, it does not stand to scrutiny when you want to have reliable forecasting of revenues.
Summary
Tracking recurring revenues is tricky and precision comes with model complexity. I find that the complexity is worth it because it instills confidence in your audiences over time and also provides the operations teams with very specific data about handling the execution on their end. For example, in the cohort-based format above, but not shown here, I would easily provide a forecasted cancellation count by age of the subscriber, which enables the operations team to manage their targets very specifically during the subscriber lifecycle journey.
One final note: this post only deals with the build up of subscribers in the future. If you have existing subscribers, you can use the same methodology but you should not mix the existing cohorts with the projected ones. The matrices go in different directions and they are hard to combine. Manage them in separate files if needed. I hope to do a post on that in the future.
FAQs for Recurring Revenue Modeling using Cohorts:
1. Why is cohort-based forecasting important in recurring revenue modeling?Cohort-based forecasting is crucial in recurring revenue modeling because it allows for a more accurate representation of revenue streams by considering variations in average revenue per subscriber and cancellation rates based on the age of the client cohorts. This approach provides a more granular and precise understanding of revenue projections, enabling better decision-making and operational strategies.
2. How does cohort-based forecasting differ from basic recurring revenue modeling?In basic recurring revenue modeling, calculations are simplified by using composite averages for revenue per subscriber and cancellation rates. In contrast, cohort-based forecasting assigns specific revenue amounts and cancellation percentages to each cohort based on their unique characteristics, such as date of birth or vintage. This results in a more detailed and nuanced analysis of revenue trends over time.
3. What are the benefits of using cohort-based forecasting in revenue modeling?Utilizing cohort-based forecasting in revenue modeling offers several advantages, including enhanced accuracy in predicting revenue fluctuations, better insights into subscriber behavior over time, and the ability to provide operations teams with specific data to optimize customer retention strategies. While this approach may introduce complexity, the precision it brings to forecasting can lead to more reliable financial projections and improved operational efficiency.